
La performance (o rendimiento) es un atributo de calidad clave para el éxito de un producto basado en software. Cada vez más, los usuarios exigen que las aplicaciones funcionen de manera rápida y fluida, y no están dispuestos a tolerar lentitud en el tiempo de respuesta de las mismas.
En la mayoría de los productos de Widergy, construimos aplicaciones en la nube, accesibles desde todo el mundo a través de internet, pensadas para escalar a millones de usuarios. Sin embargo, para que nuestras aplicaciones funcionen correctamente deben integrarse con una capa de servicios provista por los servidores de nuestros clientes (las empresas de energía). Este enlace suele estar bajo presión, es por eso que buscamos la manera de mejorar la experiencia del usuario y reducir el tráfico sobre los servidores de las Utilities.
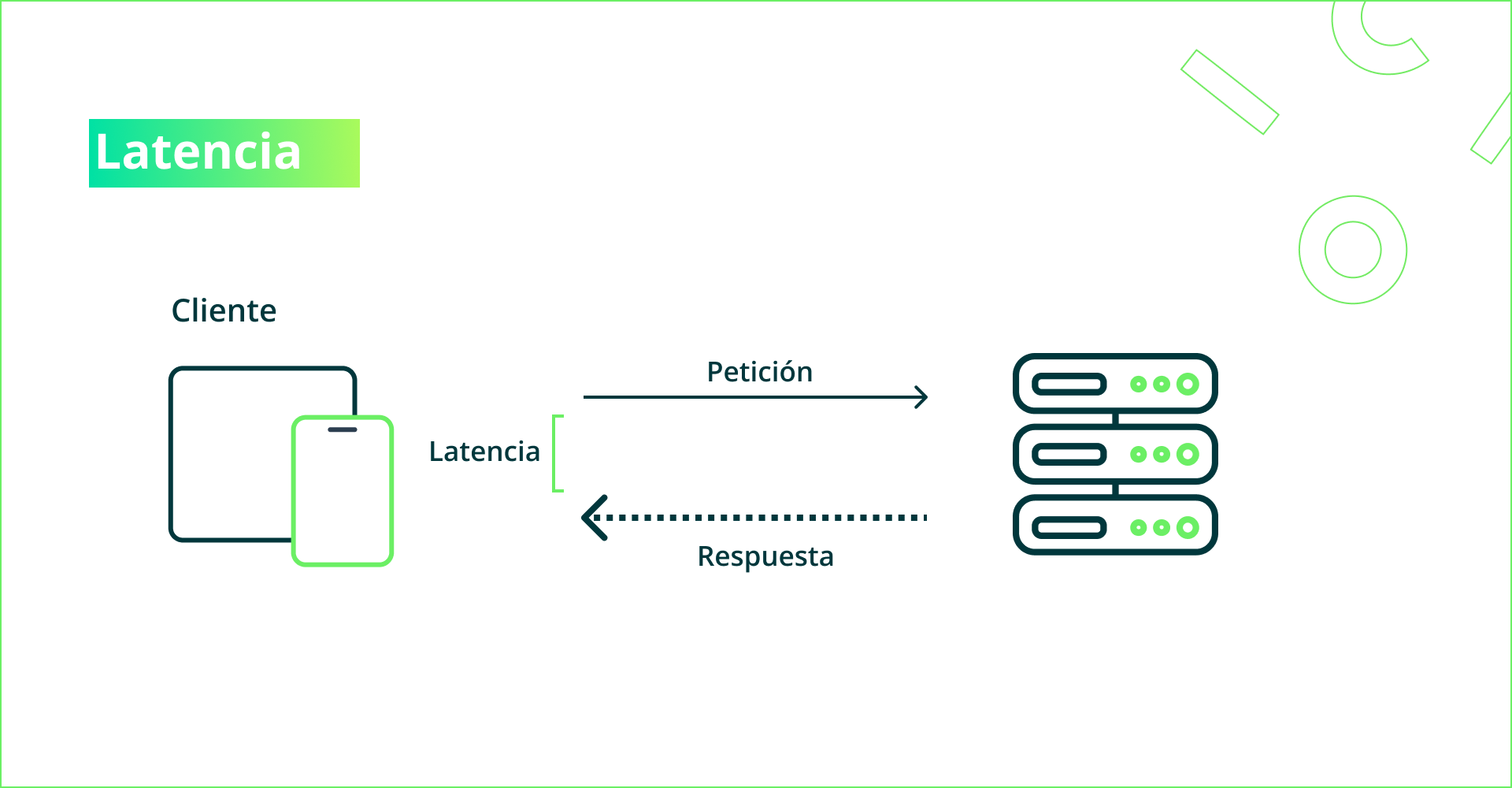
Para medir la performance de una aplicación, hay dos métricas principales que buscamos monitorear: la latencia y el throughput. La latencia es el tiempo desde que se envió una petición hasta que se obtuvo una respuesta desde el navegador web o app mobile del usuario. Esta métrica es clave para saber que tan fluida es la experiencia del usuario. El throughput en cambio es la cantidad de solicitudes que el servidor puede resolver en un intervalo de tiempo dado, es decir, determina de algún modo cuantos usuarios pueden conectarse en simultáneo.
Caching
Caching es una técnica que permite mejorar ambas métricas, a costa de mayor complejidad y espacio de almacenamiento. La idea consiste en guardar copias de datos recientemente utilizados en un almacenamiento de alta velocidad, evitando así tener que ir a consultar a la fuente origen. Este concepto sencillo se puede aplicar de manera transversal a todas las capas de una aplicación; desde el navegador web hasta los servicios del backend.
A pesar de sus ventajas, el uso de caché implica almacenamiento adicional para guardar copias de los datos y lógica aplicativa adicional para decidir cuándo ir a buscar los datos a la caché y cuándo a la fuente origen. Este último punto puede ser particularmente complejo, dado que queremos evitar mostrar al usuario versiones desactualizadas de los datos.
En este artículo, exploraremos la utilización de caching en los distintos componentes que conforman la arquitectura típica de una aplicación de Widergy.
Arquitectura típica de Widergy
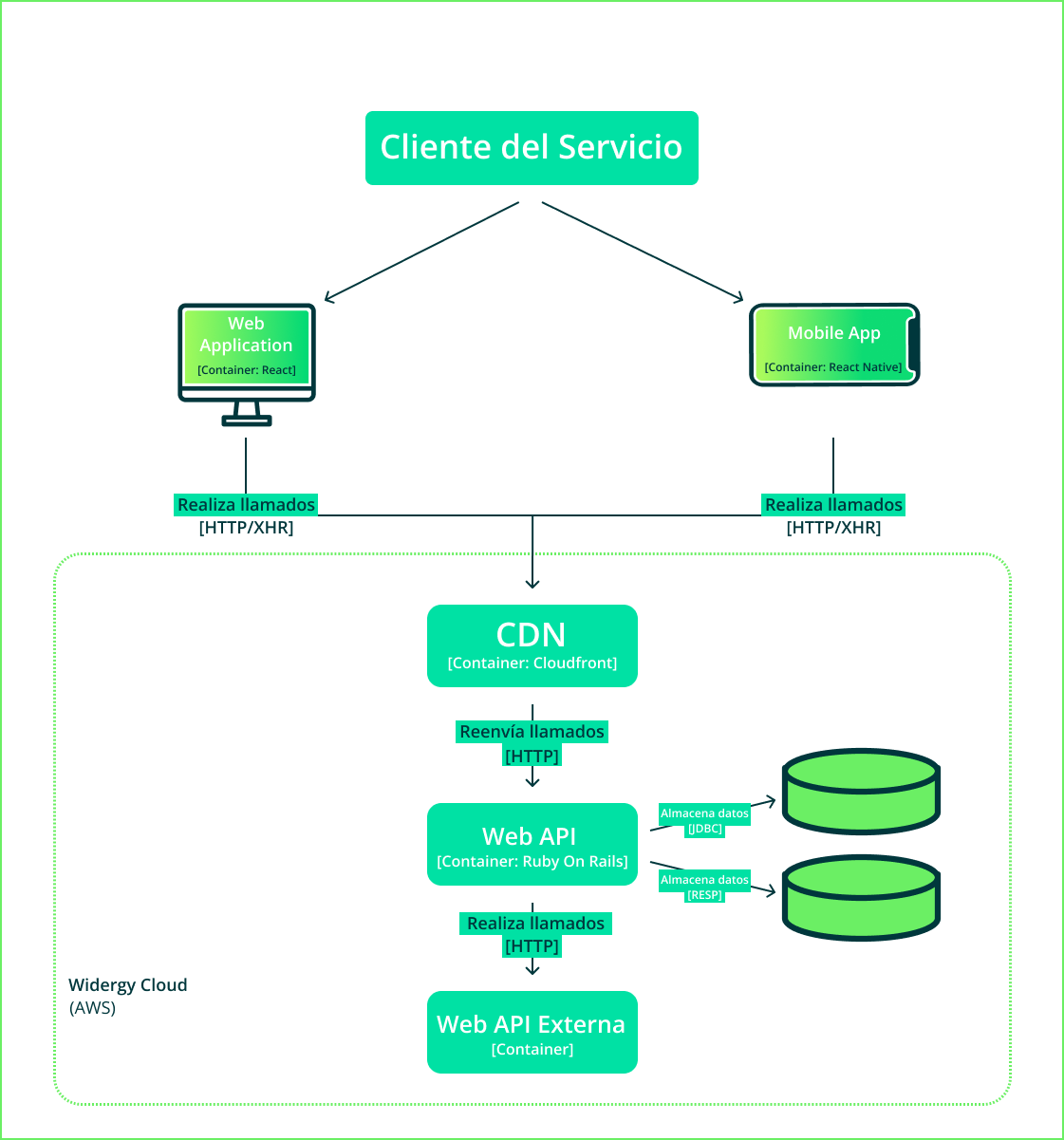
En la Figura 2, se puede observar una versión simplificada de la arquitectura de una aplicación web de un producto de Widergy. Veremos cada una de las capas, comenzando desde la más cercana al usuario final:
Aplicación Cliente
La primera capa es la aplicación cliente. Esta se ejecuta directamente en el dispositivo del usuario, ya sea mobile o desktop. Sin embargo, debe interactuar con el servidor mediante un protocolo de comunicación para obtener datos no disponibles localmente.
Content Delivery Network
Un CDN (Content Delivery Network) es una red de servidores proxy distribuidos geográficamente a nivel mundial, que sirven para servir contenido a los usuarios de manera rápida y transparente. En esta capa se puede cachear contenido que será servido directamente desde un servidor cercano, acelerando la entrega del mismo.
Web API
Una Web API es un programa que se ejecuta en servidores y provee una interfaz de servicios, necesarios para el funcionamiento de las aplicaciones cliente. Para resolver las peticiones recibidas puede consultar bases de datos de distintos tipos o realizar invocaciones a sistemas externos.
Web APIs externas
Las Web APIs externas refieren a aquellos sistemas externos al producto a los que el mismo debe comunicarse para resolver consultas.
En cada una de estas capas, se pueden utilizar distintos mecanismos de caché para lograr un funcionamiento más fluido de la aplicación. A continuación veremos conceptos generales, aplicables a todas las capas, que deben tenerse en cuenta al momento de armar una estrategia de Caching Multinivel.
Conceptos clave
Independientemente de en qué capa de aplicación se vaya a implementar la estrategia de Caching, los conceptos que compartimos a continuación serán útiles para tomar mejores decisiones en el proceso:
Interfaz de programación
Como veremos en las próximas secciones, la utilización de caché tiene sus complejidades; por lo tanto, es importante que en los programas que escribamos tengamos una interfaz de programación sencilla, que vuelva transparente la utilización de caching. Para lograr esto, introducimos el concepto del controlador de caché, que es el módulo responsable de coordinar el uso de caché.
- En la creación del controlador, se decide el tipo de almacenamiento y las políticas por defecto de expiración y de desalojo, así como otras configuraciones.
- Cuando se solicita un recurso, el controlador decide si servirlo desde la caché o ir a buscarlo al sistema origen, separando la responsabilidad del manejo caché del manejo de la solicitud puntual.
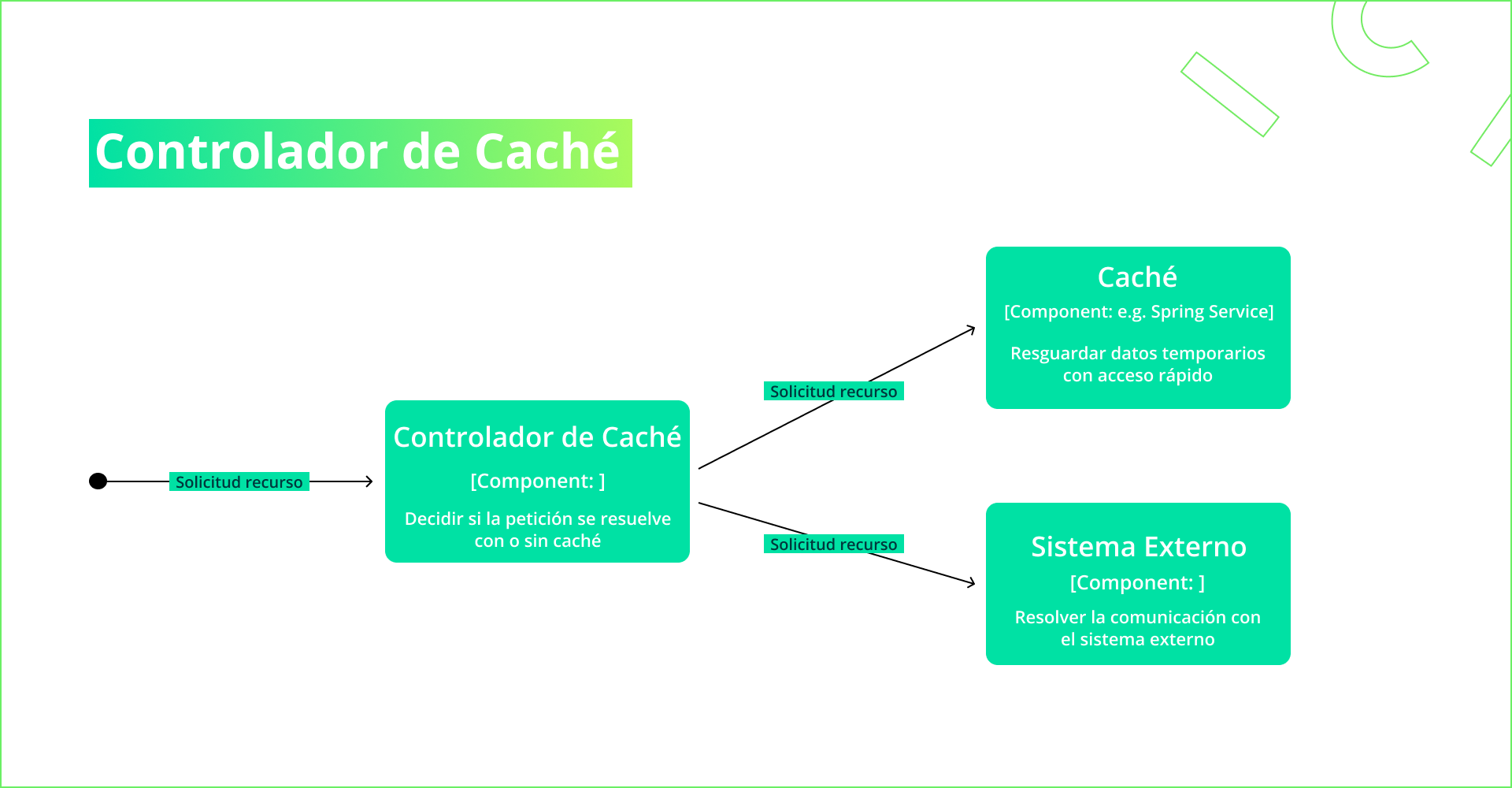
Para decidir si el dato se sirve desde la caché deben tenerse en cuenta distintos aspectos que el controlador de caché permite controlar:
Clave de caché
La caché funciona como un diccionario clave-valor, donde para cada clave guardamos un valor precalculado, junto a cierta metadata. Qué datos incluir en la clave de caché es una decisión crucial que afecta el hit-rate y puede generar falsos positivos. Por ejemplo, hablando de solicitudes HTTP, una pregunta a realizarse es qué headers deben incluirse en la clave para evitar falsos positivos.
Caché pública versus privada
Hay ciertos datos que son públicos (no requieren autenticación) y que no cambian habitualmente. Un ejemplo típico son las imágenes o datos de configuración. Para estos casos, es muy útil la utilización de las funcionalidades de caché de Cloudfront. Mediante headers HTTP especiales, podemos indicar si consideramos que un dato es público y se puede cachear en esta capa.
Expiración
La expiración es el tiempo desde que un dato se guarda en la caché hasta que se considera obsoleto. Qué valor utilizar dependerá principalmente de qué tan dispuesto se esté a arriesgarse a mostrar un dato que se encuentre desactualizado. Por lo tanto, este valor dependerá mucho del dato qué estemos guardando por lo que resulta difícil aplicar una política genérica. Mediante headers HTTP especiales, podemos indicar la expiración deseada por cada endpoint de nuestra aplicación.
Afortunadamente, suele haber una gran cantidad de datos estáticos o semi-estáticos a los que puede asignársele una expiración prolongada.
Invalidación
Es posible que una aplicación sepa en qué momento un dato en la caché deja de ser válido. Esto es normal cuando es justamente una acción del usuario. En estas situaciones, se puede realizar una invalidación manual de caché, la cual consiste en activamente borrar entradas en la memoria caché.
Políticas de escritura
Cuando desde la aplicación cliente realizamos una acción que sabemos que va a modificar contenido del sistema origen, se pueden utilizar distintas políticas de escritura:
- Escribir los datos en el sistema origen e invalidar la caché local por lo que en la próxima solicitud se deberá recurrir al sistema origen.
- Escribir los datos en la caché local y de manera asíncrona portar los cambios al sistema origen.
También es posible tener un endpoint que pueda invocar el sistema origen para informar que una entrada debe ser invalidada. En otras situaciones no es posible saber si el dato fue modificado o no y nos debemos basar únicamente en la expiración de las entradas.
Almacenamiento de caché
Los datos en la caché deben guardarse en algún tipo de almacenamiento de datos que se encuentre disponible. En resumen, hay distintos niveles de almacenamiento, con diferentes trade-offs de capacidad de almacenamiento y velocidad de acceso:
Almacenamiento en memoria RAM.
Este es el de acceso más rápido y el más limitado en espacio. Además, se debe tener en cuenta que es una memoria volátil, es decir, que es liberada cuando termina la ejecución del proceso actual. Este tipo de almacenamiento lo utilizaremos principalmente en aplicaciones cliente web o mobile, donde buscamos ofrecer una experiencia fluida al usuario.
Almacenamiento en disco.
Es más lento que la memoria RAM, pero ofrece mayor capacidad de almacenamiento, además de que permite persistir datos entre distintas sesiones. Se deben tener consideraciones adicionales para evitar la corrupción de archivos y contemplar riesgos de exfiltración de datos sensibles.
Almacenamiento en base de datos externa.
También podemos utilizar una base de datos externa. Por externa, nos referimos a que reside en un servidor distinto y nos comunicamos mediante protocolos de red. Si bien esto nos otorga más flexibilidad, deben tenerse en cuenta distintas consideraciones como la latencia del enlace.
Redis es una base de datos clave-valor con almacenamiento en memoria, ideal para ser utilizada como almacenamiento de caché.
Políticas de desalojo
El almacenamiento disponible para el uso de caché suele ser limitado, por lo tanto, deben utilizarse políticas de desalojo para decidir qué entradas borrar de la caché cuando no hay más lugar disponible. Una política de desalojo común se llama LRU (least-recently-used) y consiste en desalojar el elemento que hace más tiempo no se usa, pero también hay otras políticas de desalojo más y menos sofisticadas.
Manejo de errores de comunicación
En sistemas distribuidos complejos, es habitual que los sistemas orígenes puedan encontrarse fuera de servicio temporalmente. Para mejorar la experiencia del usuario, puede ser preferible mostrarle al mismo datos obsoletos antes de propagar el error obtenido.
Métrica – Hit Rate
Una vez que hayamos implementado nuestra estrategia de caching, vamos a medir la utilización de la misma e identificar si lo que se hizo está surtiendo efecto. Para lograr esto, la métrica más común es el hit rate, el cual nos dice qué porcentaje de las solicitudes se sirven desde la caché . Técnicamente, se define como: (hits)/(hits+miss), siendo un hit cuando un dato se recupera de la caché y un miss cuando el dato no se debe buscar en la fuente origen.
Conclusión
En definitiva, Caching es una técnica que permite mejorar la performance de nuestras aplicaciones, guardando respuestas pre-calculadas. Para poder implementarla se deben tener en cuenta la frecuencia de actualización de los datos involucrados, los requisitos de espacio de almacenamiento y la complejidad adicional que añade a la lógica de la aplicación.
Debido a estas complejidades, es importante tener en cuenta los conceptos claves descritos anteriormente para armar una estrategia de implementación exitosa. Para ello, la estrategia debe involucrar todas las capas de nuestra arquitectura de aplicación para lograr el comportamiento óptimo de cada una de ellas.
Finalmente, debemos poder medir los resultados de nuestra implementación mediante métricas como el hit rate, la latencia media o el throughput.


